
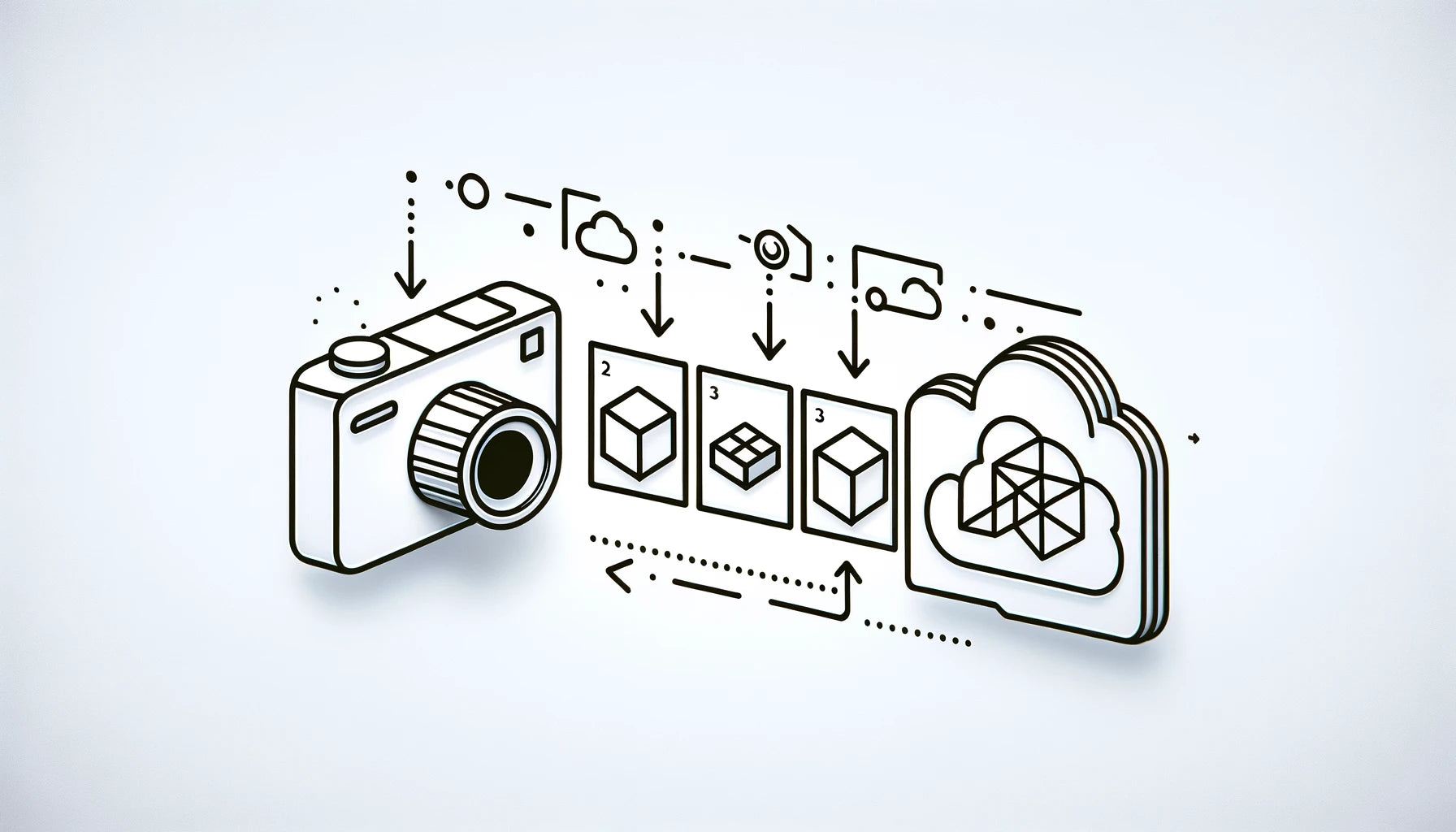
Our one-click photogrammetry solution
Use our free/donation-based processing pipeline to get amazing 3D models from any image source.
Are your photos suited for photogrammetry?
This little browser based tool will highlight areas that are most likely suitable for photogrammetry. Those red areas indicate a high feature count.
Just upload an image, adjust the grid size if you want, and click "Analyze Image" to see the heatmap of the feature density.

Before

After
Some technical details
~ 15.000 scans
~ 5.000.000 photos
>99%
in 9 minutes
~ 8%
~ 93 %
No App required!
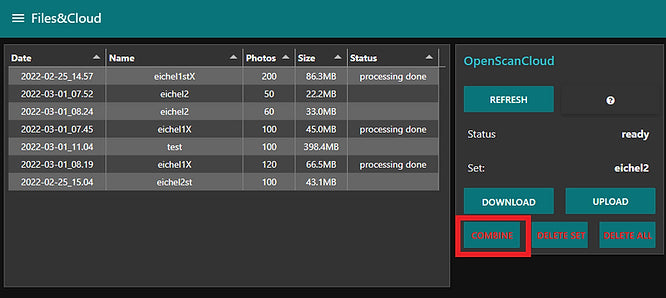
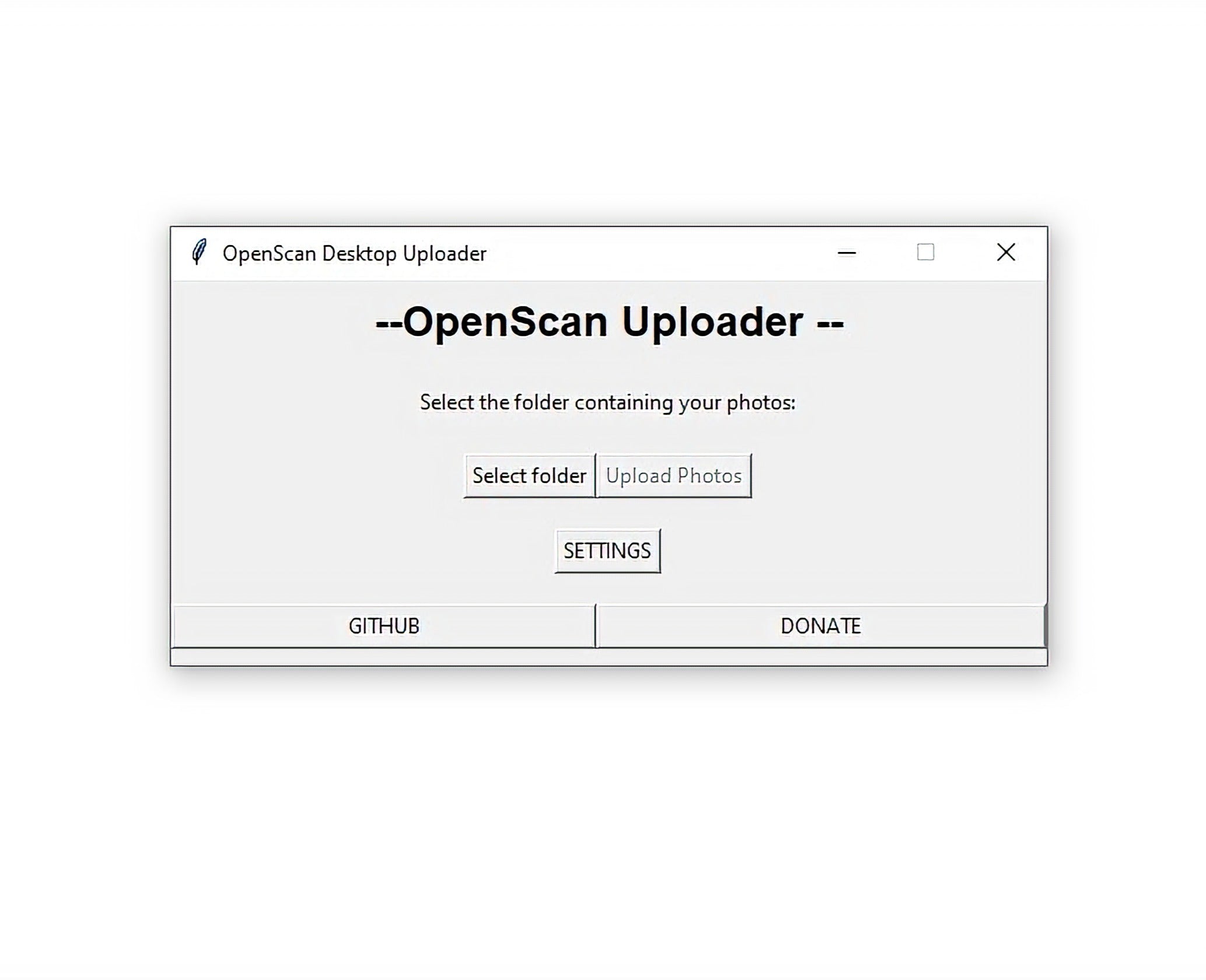
OpenScan WebUploader (BETA)
You can simply upload and process images from anywhere. The only thing needed is an access token, which can be obtained by mail to cloud@openscan.eu
Use this text to share information about your brand with your customers. Describe a product, share announcements, or welcome customers to your store.
Use this text to share information about your brand with your customers. Describe a product, share announcements, or welcome customers to your store.
Use this text to share information about your brand with your customers. Describe a product, share announcements, or welcome customers to your store.
Use this text to share information about your brand with your customers. Describe a product, share announcements, or welcome customers to your store.
Use this text to share information about your brand with your customers. Describe a product, share announcements, or welcome customers to your store.
Use this text to share information about your brand with your customers. Describe a product, share announcements, or welcome customers to your store.
Photogrammetry Software Comparison
When using Photogrammetry, which is necessary for the OpenScan Classic and Mini, you will have to choose between a wide range of available software. The OpenScan Cloud is our easy-to-use one-click-solution, but you can get similar results with many programs. We have compiled results from the same photo set (Dropbox) in various programs using standard settings (which still leave quite some room for improvements) and we will publish the results soon.
FAQ
Use this text to share information about your product or shipping policies.
Is the backend open-source?
The short answer is no! Anyway, this solution would not be suited for individuals as it requires quite a bit of infrastructure and custom setups.
What happens with your data?
The data is transferred through Dropbox and will be processed on our local servers. The data will be deleted after 7 days! (Though Dropbox keeps files up to 6 months.)
Who can use it?
Anybody is able to access the OpenScan Cloud. Keep in mind, that this service is aiming at individuals and tinkerers. If you plan commercial use, you can try it out and contact us for a possible implementation.
How to get access?
The easiest way is to send us a message to cloud@openscan.eu to request an access token.
Further questions?
Feel free to reach out through the contact form!